善用帮助文档 help create help create index ================== 1.创建索引 -在创建表时就创建(需要注意的几点) create table s1( id int ,#可以在这加primary key #id int index #不可以这样加索引,因为index只是索引,没有约束一说, #不能像主键,还有唯一约束一样,在定义字段的时候加索引 name char(20), age int, email varchar(30) #primary key(id) #也可以在这加 index(id) #可以这样加 ); -在创建表后在创建 create index name on s1(name); #添加普通索引 create unique age on s1(age);添加唯一索引 alter table s1 add primary key(id); #添加住建索引,也就是给id字段增加一个主键约束 create index name on s1(id,name); #添加普通联合索引 2.删除索引 drop index id on s1; drop index name on s1; #删除普通索引 drop index age on s1; #删除唯一索引,就和普通索引一样,不用在index前加unique来删,直接就可以删了 alter table s1 drop primary key; #删除主键(因为它添加的时候是按照alter来增加的,那么我们也用alter来删)
#1. 准备表 create table s1( id int, name varchar(20), gender char(6), email varchar(50) );
#2. 创建存储过程,实现批量插入记录 delimiter $$ #声明存储过程的结束符号为$$ create procedure auto_insert1() BEGIN declare i int default 1; while(i<3000000)do insert into s1 values(i,concat('egon',i),'male',concat('egon',i,'@oldboy')); set i=i+1; end while; END$$ #$$结束 delimiter ; #重新声明分号为结束符号
#3. 查看存储过程 show create procedure auto_insert1\G
#4. 调用存储过程 call auto_insert1();
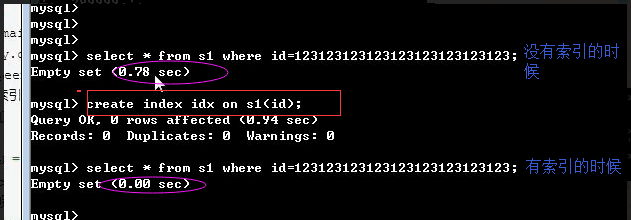
在没有索引的前提下测试查询速度
1 2 3 4 5 6 7 8 9 10 11 12 13 14
#无索引:从头到尾扫描一遍,所以查询速度很慢 mysql> select * from s1 where id=333; +------+---------+--------+----------------+ | id | name | gender | email | +------+---------+--------+----------------+ | 333 | egon333 | male | 333@oldboy.com | | 333 | egon333 | f | alex333@oldboy | | 333 | egon333 | f | alex333@oldboy | +------+---------+--------+----------------+ rows in set (0.32 sec)
mysql> select * from s1 where email='egon333@oldboy'; .... ... rows in set (0.36 sec)
加上索引
1 2 3 4 5 6 7
#1. 一定是为搜索条件的字段创建索引,比如select * from t1 where age > 5;就需要为age加上索引
#2. 在表中已经有大量数据的情况下,建索引会很慢,且占用硬盘空间,插入删除更新都很慢,只有查询快 比如create index idx on s1(id);会扫描表中所有的数据,然后以id为数据项,创建索引结构,存放于硬盘的表中。 建完以后,再查询就会很快了
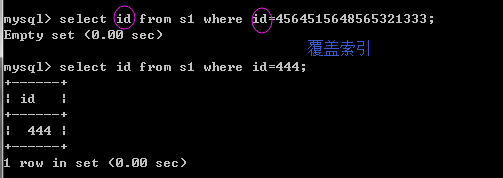
#分析 select * from s1 where id=123; 该sql命中了索引,但未覆盖索引。 利用id=123到索引的数据结构中定位到该id在硬盘中的位置,或者说再数据表中的位置。 但是我们select的字段为*,除了id以外还需要其他字段,这就意味着,我们通过索引结构取到id还不够, 还需要利用该id再去找到该id所在行的其他字段值,这是需要时间的,很明显,如果我们只select id, 就减去了这份苦恼,如下 select id from s1 where id=123; 这条就是覆盖索引了,命中索引,且从索引的数据结构直接就取到了id在硬盘的地址,速度很快
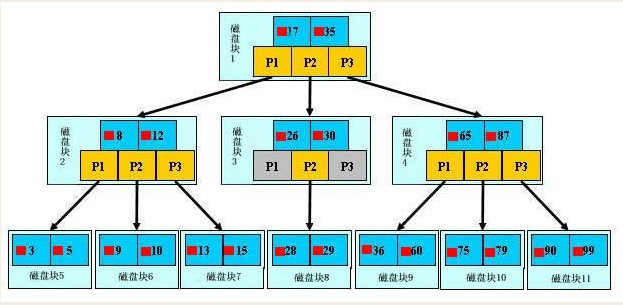
联合索引
索引合并
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
#索引合并:把多个单列索引合并使用
#分析: 组合索引能做到的事情,我们都可以用索引合并去解决,比如 create index ne on s1(name,email);#组合索引 我们完全可以单独为name和email创建索引
组合索引可以命中: select * from s1 where name='egon' ; select * from s1 where name='egon' and email='adf';
索引合并可以命中: select * from s1 where name='egon' ; select * from s1 where email='adf'; select * from s1 where name='egon' and email='adf';
乍一看好像索引合并更好了:可以命中更多的情况,但其实要分情况去看,如果是name='egon' and email='adf', 那么组合索引的效率要高于索引合并,如果是单条件查,那么还是用索引合并比较合理
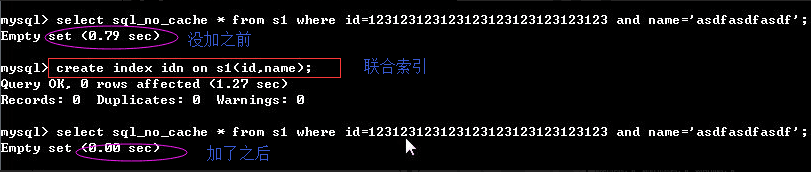
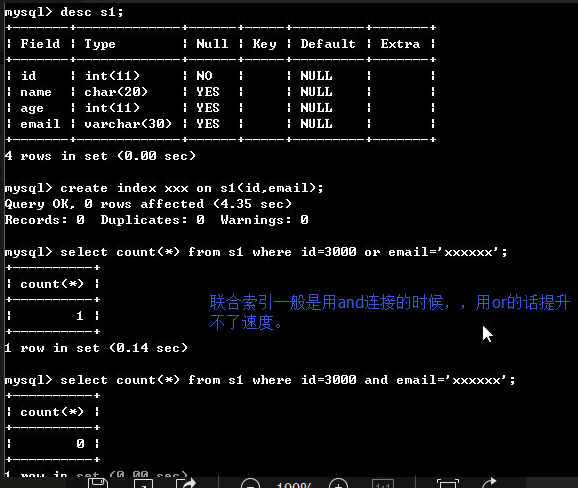
#1.最左前缀匹配原则,非常重要的原则, create index ix_name_email on s1(name,email,) - 最左前缀匹配:必须按照从左到右的顺序匹配 select * from s1 where name='egon'; #可以 select * from s1 where name='egon' and email='asdf'; #可以 select * from s1 where email='alex@oldboy.com'; #不可以 mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配, 比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引, d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
#2.=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)索引可以任意顺序,mysql的查询优化器 会帮你优化成索引可以识别的形式
. 最左前缀匹配 index(id,age,email,name) #条件中一定要出现id(只要出现id就会提升速度) id id age id email id name
email #不行 如果单独这个开头就不能提升速度了 mysql> select count(*) from s1 where id=3000; +----------+ | count(*) | +----------+ | 1 | +----------+ 1 row in set (0.11 sec)
mysql> create index xxx on s1(id,name,age,email); Query OK, 0 rows affected (6.44 sec) Records: 0 Duplicates: 0 Warnings: 0
mysql> select count(*) from s1 where id=3000; +----------+ | count(*) | +----------+ | 1 | +----------+ 1 row in set (0.00 sec)
mysql> select count(*) from s1 where name='egon'; +----------+ | count(*) | +----------+ | 299999 | +----------+ 1 row in set (0.16 sec)
mysql> select count(*) from s1 where email='egon3333@oldboy.com'; +----------+ | count(*) | +----------+ | 1 | +----------+ 1 row in set (0.15 sec)
mysql> select count(*) from s1 where id=1000 and email='egon3333@oldboy.com'; +----------+ | count(*) | +----------+ | 0 | +----------+ 1 row in set (0.00 sec)
mysql> select count(*) from s1 where email='egon3333@oldboy.com' and id=3000; +----------+ | count(*) | +----------+ | 0 | +----------+ 1 row in set (0.00 sec)
- like '%xx' select * from tb1 where email like '%cn'; - 使用函数 select * from tb1 where reverse(email) = 'wupeiqi'; - or select * from tb1 where nid = 1 or name = 'seven@live.com'; 特别的:当or条件中有未建立索引的列才失效,以下会走索引 select * from tb1 where nid = 1 or name = 'seven'; select * from tb1 where nid = 1 or name = 'seven@live.com' and email = 'alex' - 类型不一致 如果列是字符串类型,传入条件是必须用引号引起来,不然... select * from tb1 where email = 999; 普通索引的不等于不会走索引 - != select * from tb1 where email != 'alex' 特别的:如果是主键,则还是会走索引 select * from tb1 where nid != 123 - > select * from tb1 where email > 'alex' 特别的:如果是主键或索引是整数类型,则还是会走索引 select * from tb1 where nid > 123 select * from tb1 where num > 123 #排序条件为索引,则select字段必须也是索引字段,否则无法命中 - order by select name from s1 order by email desc; 当根据索引排序时候,select查询的字段如果不是索引,则不走索引 select email from s1 order by email desc; 特别的:如果对主键排序,则还是走索引: select * from tb1 order by nid desc; - 组合索引最左前缀 如果组合索引为:(name,email) name and email -- 使用索引 name -- 使用索引 email -- 不使用索引
- count(1)或count(列)代替count(*)在mysql中没有差别了
- create index xxxx on tb(title(19)) #text类型,必须制定长度