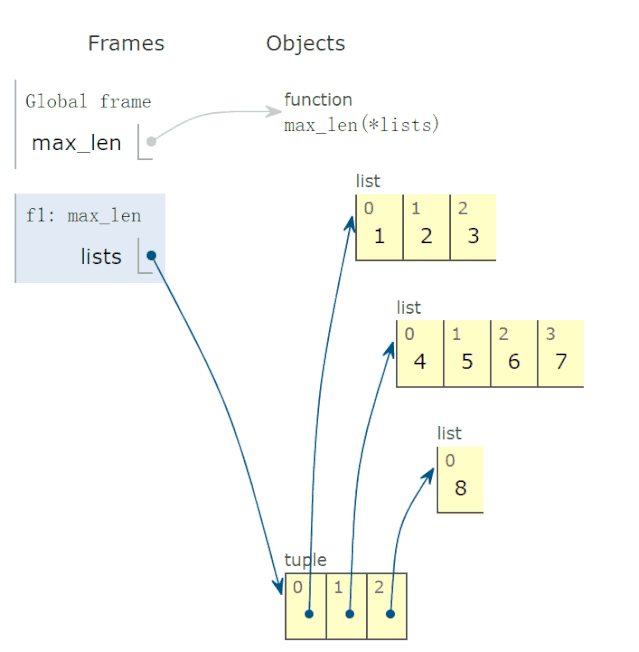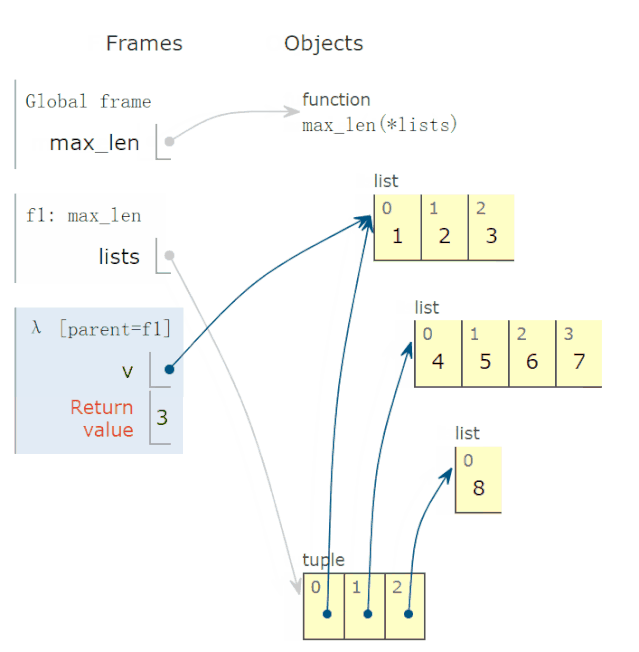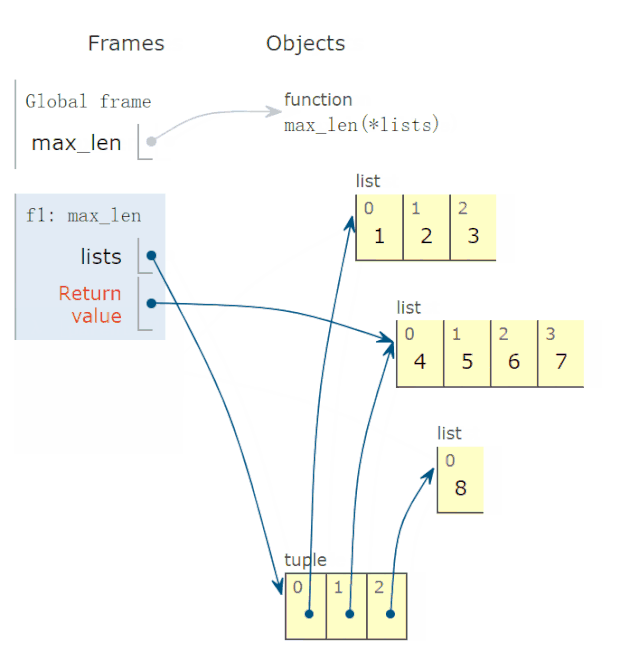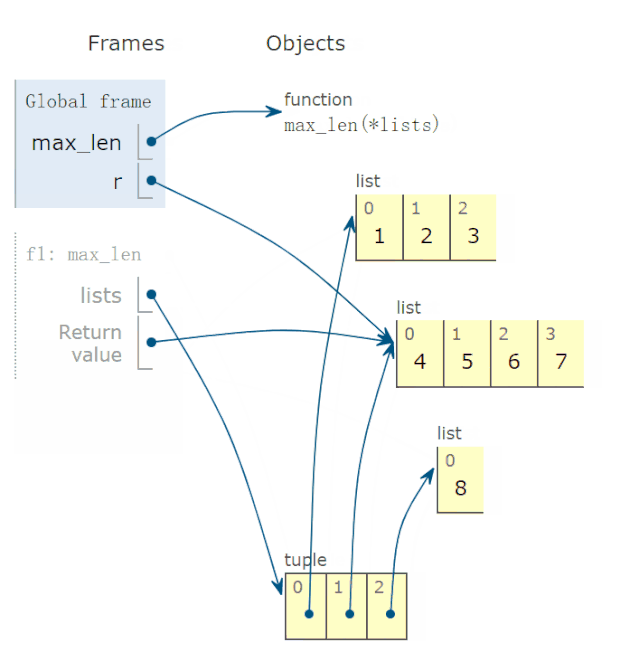
In [5]: all([1,0,3,6]) Out[5]: False In [6]: all([1,2,3]) Out[6]: True
元素至少一个为真检查
至少有一个元素为真返回True,否则False
1 2 3 4
In [7]: any([0,0,0,[]]) Out[7]: False In [8]: any([0,0,1]) Out[8]: True
判断是真是假
测试一个对象是True, 还是False
1 2 3 4 5 6 7 8
In [9]: bool([0,0,0]) Out[9]: True
In [10]: bool([]) Out[10]: False
In [11]: bool([1,0,1]) Out[11]: True
创建复数
创建一个复数
1 2
In [1]: complex(1,2) Out[1]: (1+2j)
取商和余数
分别取商和余数
1 2
In [1]: divmod(10,3) Out[1]: (3, 1)
转为浮点类型
将一个整数或数值型字符串转换为浮点数
1 2
In [1]: float(3) Out[1]: 3.0
如果不能转化为浮点数,则会报ValueError:
1 2
In [2]: float('a') # ValueError: could not convert string to float: 'a'
转为整型
int(x, base =10) , x可能为字符串或数值,将x 转换为一个普通整数。如果参数是字符串,那么它可能包含符号和小数点。如果超出了普通整数的表示范围,一个长整数被返回。
1 2
In [1]: int('12',16) Out[1]: 18
次幂
base为底的exp次幂,如果mod给出,取余
1 2
In [1]: pow(3, 2, 4) Out[1]: 1
四舍五入
四舍五入,ndigits代表小数点后保留几位:
1 2 3 4 5
In [11]: round(10.0222222, 3) Out[11]: 10.022
In [12]: round(10.05,1) Out[12]: 10.1
链式比较
1 2 3
i = 3 print(1 < i < 3) # False print(1 < i <= 3) # True
字符串
字符串转字节
字符串转换为字节类型
1 2 3 4
In [12]: s = "apple"
In [13]: bytes(s,encoding='utf-8') Out[13]: b'apple'
任意对象转为字符串
1 2 3 4 5 6 7 8 9 10
In [14]: i = 100
In [15]: str(i) Out[15]: '100'
In [16]: str([]) Out[16]: '[]'
In [17]: str(tuple()) Out[17]: '()'
执行字符串表示的代码
将字符串编译成python能识别或可执行的代码,也可以将文字读成字符串再编译。
1 2 3 4 5 6 7 8 9
In [1]: s = "print('helloworld')" In [2]: r = compile(s,"<string>", "exec") In [3]: r Out[3]: <code object <module> at 0x0000000005DE75D0, file "<string>", line 1> In [4]: exec(r) helloworld
计算表达式
将字符串str 当成有效的表达式来求值并返回计算结果取出字符串中内容
1 2 3 4
In [1]: s = "1 + 3 +5" ...: eval(s) ...: Out[1]: 9
In [22]: for name,val in signature(f).parameters.items(): ...: print(name,val.kind) ...: a KEYWORD_ONLY b VAR_KEYWORD
可看到参数a的类型为KEYWORD_ONLY,也就是仅仅为关键字参数。
但是,如果f定义为:
1 2
def f(a,*b): print(f'a:{a},b:{b}')
查看参数类型:
1 2 3 4 5
In [24]: for name,val in signature(f).parameters.items(): ...: print(name,val.kind) ...: a POSITIONAL_OR_KEYWORD b VAR_POSITIONAL
可以看到参数a既可以是位置参数也可是关键字参数。
使用slice对象
生成关于蛋糕的序列cake1:
1 2 3 4 5 6 7 8 9
In [1]: cake1 = list(range(5,0,-1))
In [2]: b = cake1[1:10:2]
In [3]: b Out[3]: [4, 2]
In [4]: cake1 Out[4]: [5, 4, 3, 2, 1]
再生成一个序列:
1 2 3 4 5 6
In [5]: from random import randint ...: cake2 = [randint(1,100) for _ in range(100)] ...: # 同样以间隔为2切前10个元素,得到切片d ...: d = cake2[1:10:2] In [6]: d Out[6]: [75, 33, 63, 93, 15]
In [16]: i_am_list = [1,3,5] In [17]: i_am_tuple = tuple(i_am_list) In [18]: i_am_tuple Out[18]: (1, 3, 5)
类和对象
是否可调用
检查对象是否可被调用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
In [1]: callable(str) Out[1]: True
In [2]: callable(int) Out[2]: True In [18]: class Student(): ...: def __init__(self,id,name): ...: self.id = id ...: self.name = name ...: def __repr__(self): ...: return 'id = '+self.id +', name = '+self.name ...
In [19]: xiaoming = Student('001','xiaoming')
In [20]: callable(xiaoming) Out[20]: False
如果能调用xiaoming(), 需要重写Student类的__call__方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
In [1]: class Student(): ...: def __init__(self,id,name): ...: self.id = id ...: self.name = name ...: def __repr__(self): ...: return 'id = '+self.id +', name = '+self.name ...: def __call__(self): ...: print('I can be called') ...: print(f'my name is {self.name}') ...:
In [2]: t = Student('001','xiaoming')
In [3]: t() I can be called my name is xiaoming
ascii 展示对象
调用对象的 repr 方法,获得该方法的返回值,如下例子返回值为字符串
1 2 3 4 5 6
>>> class Student(): def __init__(self,id,name): self.id = id self.name = name def __repr__(self): return 'id = '+self.id +', name = '+self.name
调用:
1 2 3 4 5
>>> xiaoming = Student(id='1',name='xiaoming') >>> xiaoming id = 1, name = xiaoming >>> ascii(xiaoming) 'id = 1, name = xiaoming'
In [2]: hash([1,2,3]) # TypeError: unhashable type: 'list'
一键帮助
返回对象的帮助文档
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
In [1]: help(xiaoming) Help on Student in module __main__ object:
class Student(builtins.object) | Methods defined here: | | __init__(self, id, name) | | __repr__(self) | | Data descriptors defined here: | | __dict__ | dictionary for instance variables (if defined) | | __weakref__ | list of weak references to the object (if defined)
In [2]: for i in rev: ...: print(i) ...: 1 3 2 4 1
聚合迭代器
创建一个聚合了来自每个可迭代对象中的元素的迭代器:
1 2 3 4 5 6 7 8 9 10 11
In [1]: x = [3,2,1] In [2]: y = [4,5,6] In [3]: list(zip(y,x)) Out[3]: [(4, 3), (5, 2), (6, 1)]
In [4]: a = range(5) In [5]: b = list('abcde') In [6]: b Out[6]: ['a', 'b', 'c', 'd', 'e'] In [7]: [str(y) + str(x) for x,y in zip(a,b)] Out[7]: ['a0', 'b1', 'c2', 'd3', 'e4']
链式操作
1 2 3 4 5 6 7 8
from operator import (add, sub)
def add_or_sub(a, b, oper): return (add if oper == '+' else sub)(a, b)
add_or_sub(1, 2, '-') # -1
对象序列化
对象序列化,是指将内存中的对象转化为可存储或传输的过程。很多场景,直接一个类对象,传输不方便。
但是,当对象序列化后,就会更加方便,因为约定俗成的,接口间的调用或者发起的 web 请求,一般使用 json 串传输。