goroutine调度器概述
goroutine简介
goroutine是Go语言实现的用户态线程,主要用来解决操作系统线程太“重”的问题,所谓的太重,主要表现在以下两个方面:
- 创建和切换太重:操作系统线程的创建和切换都需要进入内核,而进入内核所消耗的性能代价比较高,开销较大;
- 内存使用太重:一方面,为了尽量避免极端情况下操作系统线程栈的溢出,内核在创建操作系统线程时默认会为其分配一个较大的栈内存(虚拟地址空间,内核并不会一开始就分配这么多的物理内存),然而在绝大多数情况下,系统线程远远用不了这么多内存,这导致了浪费;另一方面,栈内存空间一旦创建和初始化完成之后其大小就不能再有变化,这决定了在某些特殊场景下系统线程栈还是有溢出的风险。
而相对的,用户态的goroutine则轻量得多:
- goroutine是用户态线程,其创建和切换都在用户代码中完成而无需进入操作系统内核,所以其开销要远远小于系统线程的创建和切换;
- goroutine启动时默认栈大小只有2k,这在多数情况下已经够用了,即使不够用,goroutine的栈也会自动扩大,同时,如果栈太大了过于浪费它还能自动收缩,这样既没有栈溢出的风险,也不会造成栈内存空间的大量浪费。
正是因为Go语言中实现了如此轻量级的线程,才使得我们在Go程序中,可以轻易的创建成千上万甚至上百万的goroutine出来并发的执行任务而不用太担心性能和内存等问题。
注意: 为了避免混淆,从现在开始,后面出现的所有的线程一词均是指操作系统线程,而goroutine我们不再称之为什么什么线程而是直接使用goroutine这个词。
线程模型与调度器
第一章讨论操作系统线程调度的时候我们曾经提到过,goroutine建立在操作系统线程基础之上,它与操作系统线程之间实现了一个多对多(M:N)的两级线程模型。
这里的 M:N 是指M个goroutine运行在N个操作系统线程之上,内核负责对这N个操作系统线程进行调度,而这N个系统线程又负责对这M个goroutine进行调度和运行。
所谓的对goroutine的调度,是指程序代码按照一定的算法在适当的时候挑选出合适的goroutine并放到CPU上去运行的过程,这些负责对goroutine进行调度的程序代码我们称之为goroutine调度器。用极度简化了的伪代码来描述goroutine调度器的工作流程大概是下面这个样子:
1 | // 程序启动时的初始化代码 |
这段伪代码表达的意思是,程序运行起来之后创建了N个由内核调度的操作系统线程(为了方便描述,我们称这些系统线程为工作线程)去执行shedule函数,而schedule函数在一个调度循环中反复从M个goroutine中挑选出一个需要运行的goroutine并跳转到该goroutine去运行,直到需要调度其它goroutine时才返回到schedule函数中通过save_status_of_g保存刚刚正在运行的goroutine的状态然后再次去寻找下一个goroutine。
需要强调的是,这段伪代码对goroutine的调度代码做了高度的抽象、修改和简化处理,放在这里只是为了帮助我们从宏观上了解goroutine的两级调度模型,具体的实现原理和细节将从本章开始进行全面介绍。
调度器数据结构概述
第一章我们讨论操作系统线程及其调度时还说过,可以把内核对系统线程的调度简单的归纳为:在执行操作系统代码时,内核调度器按照一定的算法挑选出一个线程并把该线程保存在内存之中的寄存器的值放入CPU对应的寄存器从而恢复该线程的运行。
万变不离其宗,系统线程对goroutine的调度与内核对系统线程的调度原理是一样的,实质都是通过保存和修改CPU寄存器的值来达到切换线程/goroutine的目的。
因此,为了实现对goroutine的调度,需要引入一个数据结构来保存CPU寄存器的值以及goroutine的其它一些状态信息,在Go语言调度器源代码中,这个数据结构是一个名叫g的结构体,它保存了goroutine的所有信息,该结构体的每一个实例对象都代表了一个goroutine,调度器代码可以通过g对象来对goroutine进行调度,当goroutine被调离CPU时,调度器代码负责把CPU寄存器的值保存在g对象的成员变量之中,当goroutine被调度起来运行时,调度器代码又负责把g对象的成员变量所保存的寄存器的值恢复到CPU的寄存器。
要实现对goroutine的调度,仅仅有g结构体对象是不够的,至少还需要一个存放所有(可运行)goroutine的容器,便于工作线程寻找需要被调度起来运行的goroutine,于是Go调度器又引入了schedt结构体,一方面用来保存调度器自身的状态信息,另一方面它还拥有一个用来保存goroutine的运行队列。因为每个Go程序只有一个调度器,所以在每个Go程序中schedt结构体只有一个实例对象,该实例对象在源代码中被定义成了一个共享的全局变量,这样每个工作线程都可以访问它以及它所拥有的goroutine运行队列,我们称这个运行队列为全局运行队列。
既然说到全局运行队列,读者可能猜想到应该还有一个局部运行队列。确实如此,因为全局运行队列是每个工作线程都可以读写的,因此访问它需要加锁,然而在一个繁忙的系统中,加锁会导致严重的性能问题。于是,调度器又为每个工作线程引入了一个私有的局部goroutine运行队列,工作线程优先使用自己的局部运行队列,只有必要时才会去访问全局运行队列,这大大减少了锁冲突,提高了工作线程的并发性。在Go调度器源代码中,局部运行队列被包含在p结构体的实例对象之中,每一个运行着go代码的工作线程都会与一个p结构体的实例对象关联在一起。
除了上面介绍的g、schedt和p结构体,Go调度器源代码中还有一个用来代表工作线程的m结构体,每个工作线程都有唯一的一个m结构体的实例对象与之对应,m结构体对象除了记录着工作线程的诸如栈的起止位置、当前正在执行的goroutine以及是否空闲等等状态信息之外,还通过指针维持着与p结构体的实例对象之间的绑定关系。于是,通过m既可以找到与之对应的工作线程正在运行的goroutine,又可以找到工作线程的局部运行队列等资源。下面是g、p、m和schedt之间的关系图:
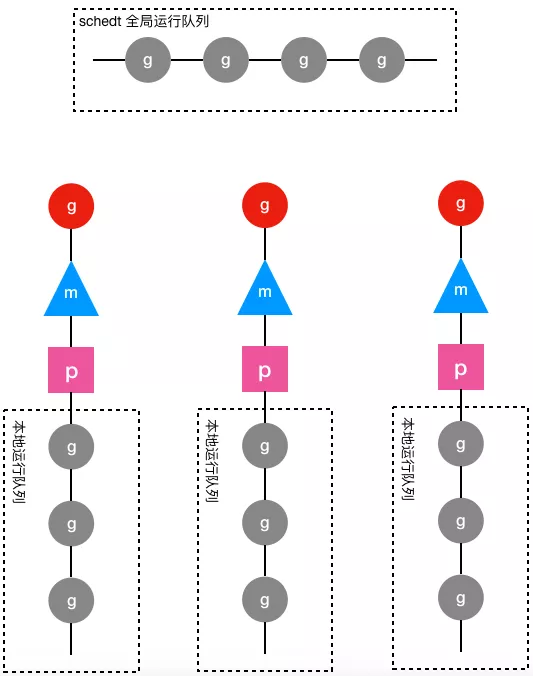
上图中圆形图案代表g结构体的实例对象,三角形代表m结构体的实例对象,正方形代表p结构体的实例对象,其中红色的g表示m对应的工作线程正在运行的goroutine,而灰色的g表示处于运行队列之中正在等待被调度起来运行的goroutine。
从上图可以看出,每个m都绑定了一个p,每个p都有一个私有的本地goroutine队列,m对应的线程从本地和全局goroutine队列中获取goroutine并运行之。
前面我们说每个工作线程都有一个m结构体对象与之对应,但并未详细说明它们之间是如何对应起来的,工作线程执行的代码是如何找到属于自己的那个m结构体实例对象的呢?
如果只有一个工作线程,那么就只会有一个m结构体对象,问题就很简单,定义一个全局的m结构体变量就行了。可是我们有多个工作线程和多个m需要一一对应,怎么办呢?还记得第一章我们讨论过的线程本地存储吗?当时我们说过,线程本地存储其实就是线程私有的全局变量,这不正是我们所需要的吗?!只要每个工作线程拥有了各自私有的m结构体全局变量,我们就能在不同的工作线程中使用相同的全局变量名来访问不同的m结构体对象,这完美的解决我们的问题。
具体到goroutine调度器代码,每个工作线程在刚刚被创建出来进入调度循环之前就利用线程本地存储机制为该工作线程实现了一个指向m结构体实例对象的私有全局变量,这样在之后的代码中就使用该全局变量来访问自己的m结构体对象以及与m相关联的p和g对象。
有了上述数据结构以及工作线程与数据结构之间的映射机制,我们可以把前面的调度伪代码写得更丰满一点:
1 | // 程序启动时的初始化代码 |
仅仅从上面这个伪代码来看,我们完全不需要线程私有全局变量,只需在schedule函数中定义一个局部变量就行了。但真实的调度代码错综复杂,不光是这个schedule函数会需要访问m,其它很多地方还需要访问它,所以需要使用全局变量来方便其它地方对m的以及与m相关的g和p的访问。
在简单的介绍了Go语言调度器以及它所需要的数据结构之后,下面我们来看一下Go的调度代码中对上述的几个结构体的定义。
重要的结构体
下面介绍的这些结构体中的字段非常多,牵涉到的细节也很庞杂,光是看这些结构体的定义我们没有必要也无法真正理解它们的用途,所以在这里我们只需要大概了解一下就行了,看不懂记不住都没有关系,随着后面对代码逐步深入的分析,我们也必将会对这些结构体有越来越清晰的认识。为了节省篇幅,下面各结构体的定义略去了跟调度器无关的成员。另外,这些结构体的定义全部位于Go语言的源代码路径下的runtime/runtime2.go文件之中。
stack结构体
stack结构体主要用来记录goroutine所使用的栈的信息,包括栈顶和栈底位置:
1 | // Stack describes a Go execution stack. |
gobuf结构体
gobuf结构体用于保存goroutine的调度信息,主要包括CPU的几个寄存器的值:
1 | type gobuf struct { |
g结构体
g结构体用于代表一个goroutine,该结构体保存了goroutine的所有信息,包括栈,gobuf结构体和其它的一些状态信息:
1 | // 前文所说的g结构体,它代表了一个goroutine |
m结构体
m结构体用来代表工作线程,它保存了m自身使用的栈信息,当前正在运行的goroutine以及与m绑定的p等信息,详见下面定义中的注释:
1 | type m struct { |
p结构体
p结构体用于保存工作线程执行go代码时所必需的资源,比如goroutine的运行队列,内存分配用到的缓存等等。
1 | type p struct { |
schedt结构体
schedt结构体用来保存调度器的状态信息和goroutine的全局运行队列:
1 | type schedt struct { |
重要的全局变量
1 | allgs []*g // 保存所有的g |
在程序初始化时,这些全变量都会被初始化为0值,指针会被初始化为nil指针,切片初始化为nil切片,int被初始化为数字0,结构体的所有成员变量按其本类型初始化为其类型的0值。所以程序刚启动时allgs,allm和allp都不包含任何g,m和p。