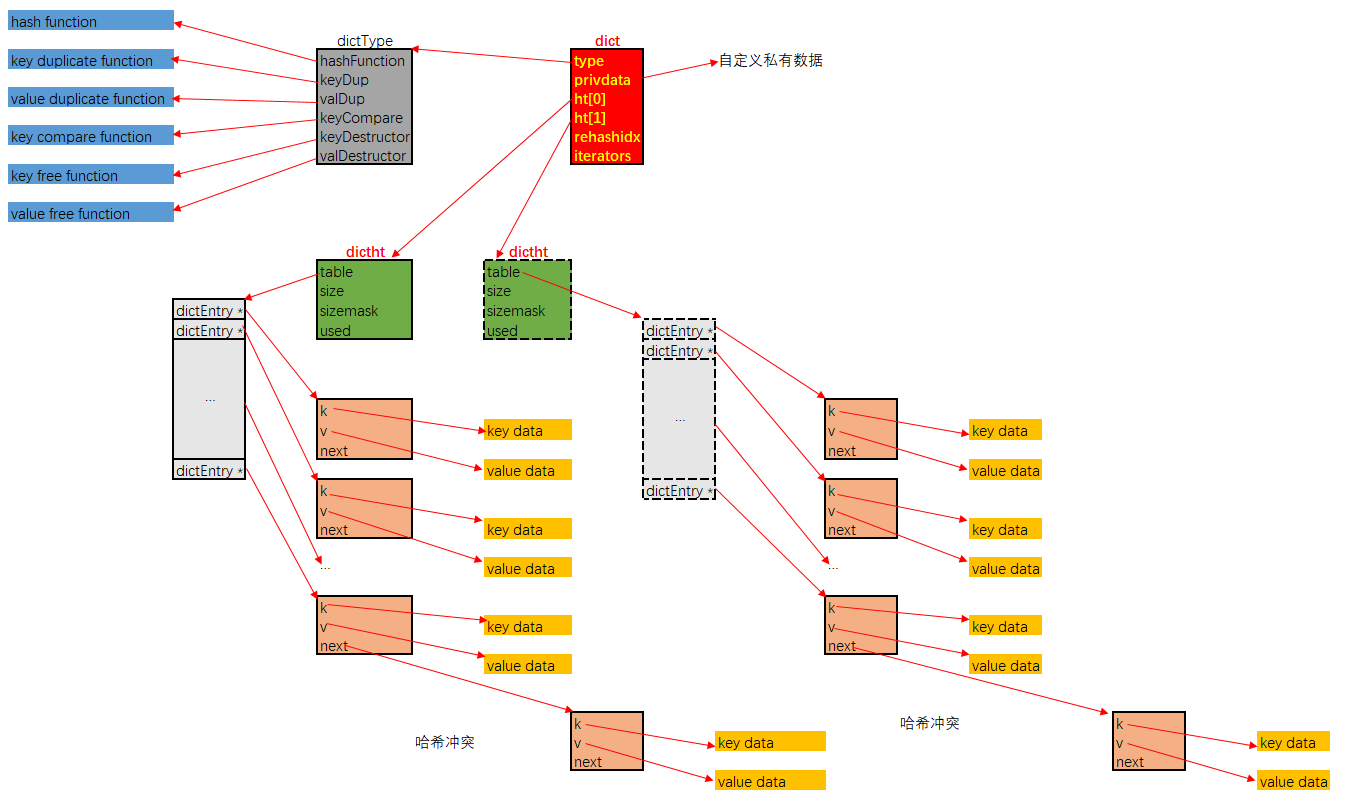
/* This is our hash table structure. Every dictionary has two of this as we * implement incremental rehashing, for the old to the new table. */ typedef struct dictht { dictEntry **table; unsigned long size; unsigned long sizemask; unsigned long used; } dictht;
typedef struct dict { dictType *type; void *privdata; dictht ht[2]; long rehashidx; /* rehashing not in progress if rehashidx == -1 */ unsigned long iterators; /* number of iterators currently running */ } dict;
/* If safe is set to 1 this is a safe iterator, that means, you can call * dictAdd, dictFind, and other functions against the dictionary even while * iterating. Otherwise it is a non safe iterator, and only dictNext() * should be called while iterating. */ typedef struct dictIterator { dict *d; long index; int table, safe; dictEntry *entry, *nextEntry; /* unsafe iterator fingerprint for misuse detection. */ long long fingerprint; } dictIterator;
/* Allocate the memory and store the new entry. * Insert the element in top, with the assumption that in a database * system it is more likely that recently added entries are accessed * more frequently. */ ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; entry = zmalloc(sizeof(*entry)); entry->next = ht->table[index]; ht->table[index] = entry; ht->used++;
/* Set the hash entry fields. */ dictSetKey(d, entry, key); return entry; }
static long _dictKeyIndex(dict *d, const void *key, uint64_t hash, dictEntry **existing) { unsigned long idx, table; dictEntry *he; if (existing) *existing = NULL;
/* Expand the hash table if needed */ if (_dictExpandIfNeeded(d) == DICT_ERR) // 探测是否需要扩容, 如果需要, 则开始扩容 return -1; for (table = 0; table <= 1; table++) { idx = hash & d->ht[table].sizemask; /* Search if this slot does not already contain the given key */ he = d->ht[table].table[idx]; while(he) { if (key==he->key || dictCompareKeys(d, key, he->key)) { if (existing) *existing = he; return -1; } he = he->next; } if (!dictIsRehashing(d)) break; } return idx; }
/* Expand the hash table if needed */ static int _dictExpandIfNeeded(dict *d) { /* Incremental rehashing already in progress. Return. */ if (dictIsRehashing(d)) return DICT_OK; // 如果正在扩容过程中, 则什么也不做
/* If the hash table is empty expand it to the initial size. */ // 若字典中本无元素, 则初始化字典, 初始化时的bucket数组长度为4 if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash * table (global setting) or we should avoid it but the ratio between * elements/buckets is over the "safe" threshold, we resize doubling * the number of buckets. */ // 若字典中元素的个数与bucket数组长度比值大于1:1时, 则调用dictExpand进入平滑扩容状态 if (d->ht[0].used >= d->ht[0].size && (dict_can_resize || d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) { return dictExpand(d, d->ht[0].used*2); } return DICT_OK; }
int dictExpand(dict *d, unsigned long size) { dictht n; /* the new hash table */ // 新建一个dictht结构 unsigned long realsize = _dictNextPower(size);
/* the size is invalid if it is smaller than the number of * elements already inside the hash table */ if (dictIsRehashing(d) || d->ht[0].used > size) return DICT_ERR;
/* Rehashing to the same table size is not useful. */ if (realsize == d->ht[0].size) return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */ n.size = realsize; n.sizemask = realsize-1; n.table = zcalloc(realsize*sizeof(dictEntry*));// 初始化dictht下的table, 即bucket数组 n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing * we just set the first hash table so that it can accept keys. */ // 若是新字典初始化, 直接把dictht结构挂在ht[0]中 if (d->ht[0].table == NULL) { d->ht[0] = n; return DICT_OK; }
// 否则, 把新dictht结构挂在ht[1]中, 并开启平滑扩容(置rehashidx为0, 字典处于非扩容状态时, 该字段值为-1) /* Prepare a second hash table for incremental rehashing */ d->ht[1] = n; d->rehashidx = 0; return DICT_OK; }
/* Note that rehashidx can't overflow as we are sure there are more * elements because ht[0].used != 0 */ assert(d->ht[0].size > (unsigned long)d->rehashidx); // 在旧bucket中, 找到下一个非空的索引位 while(d->ht[0].table[d->rehashidx] == NULL) { d->rehashidx++; if (--empty_visits == 0) return 1; } // 取出该索引位上的结点链表 de = d->ht[0].table[d->rehashidx]; /* Move all the keys in this bucket from the old to the new hash HT */ // 把所有结点迁移到新bucket中去 while(de) { uint64_t h;
nextde = de->next; /* Get the index in the new hash table */ h = dictHashKey(d, de->key) & d->ht[1].sizemask; de->next = d->ht[1].table[h]; d->ht[1].table[h] = de; d->ht[0].used--; d->ht[1].used++; de = nextde; } d->ht[0].table[d->rehashidx] = NULL; d->rehashidx++; }
/* Check if we already rehashed the whole table... */ // 检查是否旧表中的所有结点都被迁移到了新表 // 如果是, 则置先释放原旧bucket数组, 再置ht[1]为ht[0] // 最后再置rehashidx=-1, 以示字典不处于平滑扩容状态 if (d->ht[0].used == 0) { zfree(d->ht[0].table); d->ht[0] = d->ht[1]; _dictReset(&d->ht[1]); d->rehashidx = -1; return 0; }
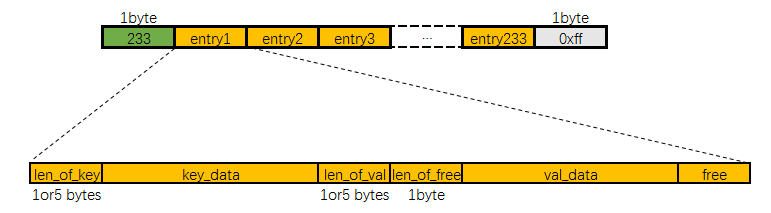
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) { size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen; unsigned int prevlensize, prevlen = 0; size_t offset; int nextdiff = 0; unsigned char encoding = 0; long long value = 123456789; /* initialized to avoid warning. Using a value that is easy to see if for some reason we use it uninitialized. */ zlentry tail;
/* Find out prevlen for the entry that is inserted. */ if (p[0] != ZIP_END) { ZIP_DECODE_PREVLEN(p, prevlensize, prevlen); } else { unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl); if (ptail[0] != ZIP_END) { prevlen = zipRawEntryLength(ptail); } }
/* See if the entry can be encoded */ if (zipTryEncoding(s,slen,&value,&encoding)) { /* 'encoding' is set to the appropriate integer encoding */ reqlen = zipIntSize(encoding); } else { /* 'encoding' is untouched, however zipStoreEntryEncoding will use the * string length to figure out how to encode it. */ reqlen = slen; } /* We need space for both the length of the previous entry and * the length of the payload. */ reqlen += zipStorePrevEntryLength(NULL,prevlen); reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
/* When the insert position is not equal to the tail, we need to * make sure that the next entry can hold this entry's length in * its prevlen field. */ int forcelarge = 0; nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0; if (nextdiff == -4 && reqlen < 4) { nextdiff = 0; forcelarge = 1; }
/* Store offset because a realloc may change the address of zl. */ offset = p-zl; zl = ziplistResize(zl,curlen+reqlen+nextdiff); p = zl+offset;
/* Apply memory move when necessary and update tail offset. */ if (p[0] != ZIP_END) { /* Subtract one because of the ZIP_END bytes */ memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* Encode this entry's raw length in the next entry. */ if (forcelarge) zipStorePrevEntryLengthLarge(p+reqlen,reqlen); else zipStorePrevEntryLength(p+reqlen,reqlen);
/* Update offset for tail */ ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* When the tail contains more than one entry, we need to take * "nextdiff" in account as well. Otherwise, a change in the * size of prevlen doesn't have an effect on the *tail* offset. */ zipEntry(p+reqlen, &tail); if (p[reqlen+tail.headersize+tail.len] != ZIP_END) { ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff); } } else { /* This element will be the new tail. */ ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl); }
/* When nextdiff != 0, the raw length of the next entry has changed, so * we need to cascade the update throughout the ziplist */ if (nextdiff != 0) { offset = p-zl; zl = __ziplistCascadeUpdate(zl,p+reqlen); p = zl+offset; }
/* Write the entry */ p += zipStorePrevEntryLength(p,prevlen); p += zipStoreEntryEncoding(p,encoding,slen); if (ZIP_IS_STR(encoding)) { memcpy(p,s,slen); } else { zipSaveInteger(p,value,encoding); } ZIPLIST_INCR_LENGTH(zl,1); return zl; }
/* Abort if there is no next entry. */ if (p[rawlen] == ZIP_END) break; zipEntry(p+rawlen, &next);
/* Abort when "prevlen" has not changed. */ if (next.prevrawlen == rawlen) break;
if (next.prevrawlensize < rawlensize) { /* The "prevlen" field of "next" needs more bytes to hold * the raw length of "cur". */ offset = p-zl; extra = rawlensize-next.prevrawlensize; zl = ziplistResize(zl,curlen+extra); p = zl+offset;
/* Current pointer and offset for next element. */ np = p+rawlen; noffset = np-zl;
/* Update tail offset when next element is not the tail element. */ if ((zl+intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))) != np) { ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+extra); }
/* Move the tail to the back. */ memmove(np+rawlensize, np+next.prevrawlensize, curlen-noffset-next.prevrawlensize-1); zipStorePrevEntryLength(np,rawlen);
/* Advance the cursor */ p += rawlen; curlen += extra; } else { if (next.prevrawlensize > rawlensize) { /* This would result in shrinking, which we want to avoid. * So, set "rawlen" in the available bytes. */ zipStorePrevEntryLengthLarge(p+rawlen,rawlen); } else { zipStorePrevEntryLength(p+rawlen,rawlen); }
/* Stop here, as the raw length of "next" has not changed. */ break; } } return zl; }
/* Node, quicklist, and Iterator are the only data structures used currently. */
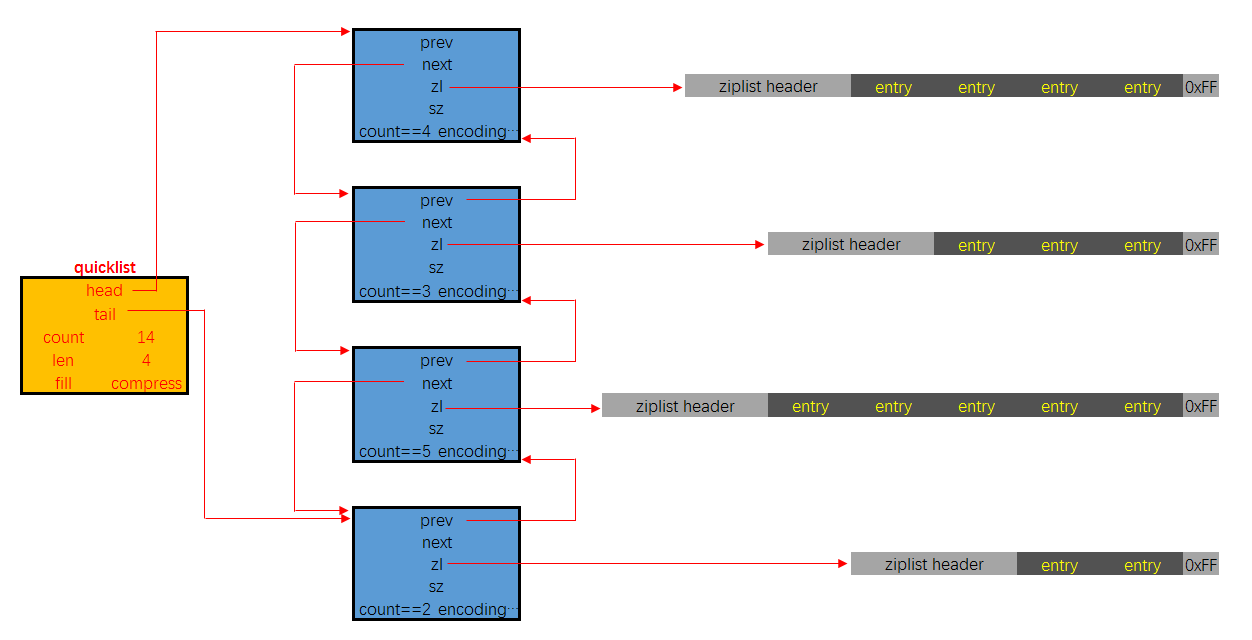
/* quicklistNode is a 32 byte struct describing a ziplist for a quicklist. * We use bit fields keep the quicklistNode at 32 bytes. * count: 16 bits, max 65536 (max zl bytes is 65k, so max count actually < 32k). * encoding: 2 bits, RAW=1, LZF=2. * container: 2 bits, NONE=1, ZIPLIST=2. * recompress: 1 bit, bool, true if node is temporarry decompressed for usage. * attempted_compress: 1 bit, boolean, used for verifying during testing. * extra: 12 bits, free for future use; pads out the remainder of 32 bits */ typedef struct quicklistNode { struct quicklistNode *prev; struct quicklistNode *next; unsigned char *zl; unsigned int sz; /* ziplist size in bytes */ unsigned int count : 16; /* count of items in ziplist */ unsigned int encoding : 2; /* RAW==1 or LZF==2 */ unsigned int container : 2; /* NONE==1 or ZIPLIST==2 */ unsigned int recompress : 1; /* was this node previous compressed? */ unsigned int attempted_compress : 1; /* node can't compress; too small */ unsigned int extra : 10; /* more bits to steal for future usage */ } quicklistNode;
/* quicklistLZF is a 4+N byte struct holding 'sz' followed by 'compressed'. * 'sz' is byte length of 'compressed' field. * 'compressed' is LZF data with total (compressed) length 'sz' * NOTE: uncompressed length is stored in quicklistNode->sz. * When quicklistNode->zl is compressed, node->zl points to a quicklistLZF */ typedef struct quicklistLZF { unsigned int sz; /* LZF size in bytes*/ char compressed[]; } quicklistLZF;
/* quicklist is a 40 byte struct (on 64-bit systems) describing a quicklist. * 'count' is the number of total entries. * 'len' is the number of quicklist nodes. * 'compress' is: -1 if compression disabled, otherwise it's the number * of quicklistNodes to leave uncompressed at ends of quicklist. * 'fill' is the user-requested (or default) fill factor. */ typedef struct quicklist { quicklistNode *head; quicklistNode *tail; unsigned long count; /* total count of all entries in all ziplists */ unsigned long len; /* number of quicklistNodes */ int fill : 16; /* fill factor for individual nodes */ unsigned int compress : 16; /* depth of end nodes not to compress;0=off */ } quicklist;
typedef struct quicklistIter { const quicklist *quicklist; quicklistNode *current; unsigned char *zi; long offset; /* offset in current ziplist */ int direction; } quicklistIter;
typedef struct quicklistEntry { const quicklist *quicklist; quicklistNode *node; unsigned char *zi; unsigned char *value; long long longval; unsigned int sz; int offset; } quicklistEntry;